Scientific background
Archetypal phonemes in speech

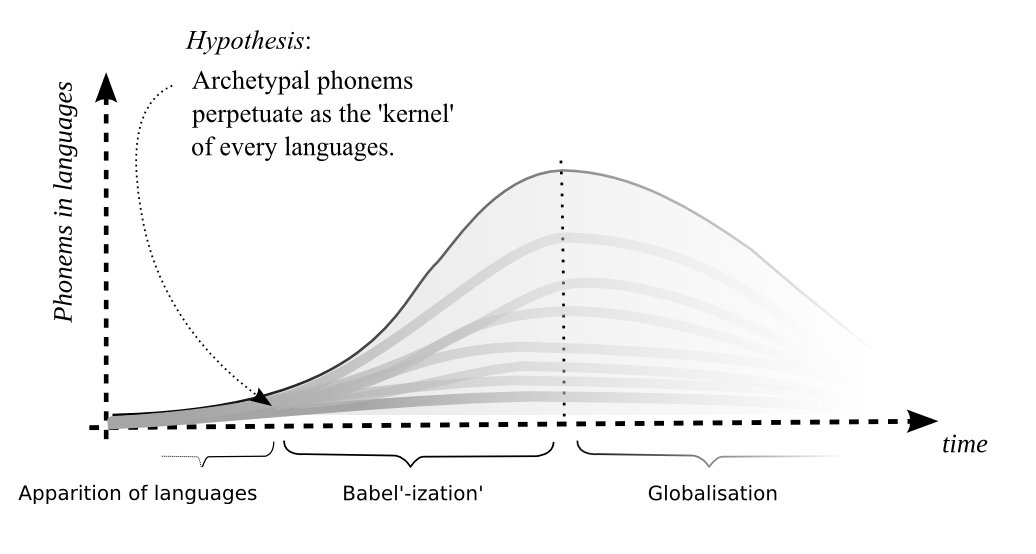
Finding a universal identification of phonemes independently from the language is controversial from the linguistic point of view (because it is usually established that each language is based on its own set of phoneme (e.g. 62 in English, 32 in French or 28 in Italian), but it has a philosophical and historical basis. In his study on the apparition of articulated language in human pre-history 1, Marcel Locquin defines twenty archetypal phonemes in human languages which would have formed the roots of every current languages. These twenty archetypal phonemes were identified in elementary sounds of baby talk and in 80 extinct and 50 living languages. This does not mean that all started in one place with a single population of individuals, but that the apparition of language was simply bound to the morphological and cognitive abilities of our ancestors. The multiplication of languages would then be similar to the common phenomenon observed between "villages", where particularities of the phones (diacrites) make it possible to recognize the identity of their original village by their neighboring villagers. More well known is the regional accents existing in most languages, sometime to the point of making comprehension impossible, or even, as in the case of American English, becoming another languages. If there were fewer phonemes in the beginning of languages, the multiplicity of languages increased the number of phonemes; but today's increased communication in the globalization age may as well decrease the number of phonemes (see figure above).
{kind=link}
Speech analysis
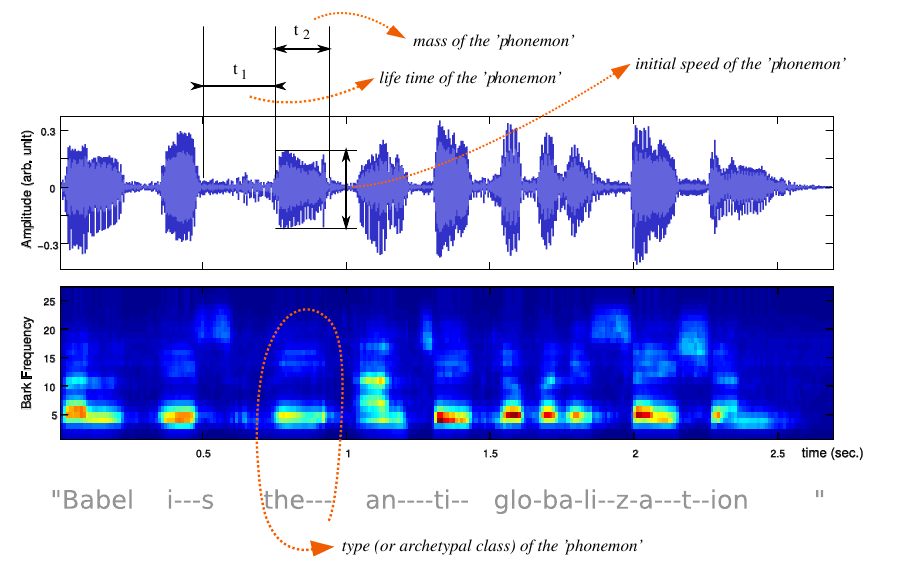
The singer stores a pre-defined selection of 'snapshots' of vowels in computer memory. Each vowel is described as a vector on the Bark scale, and a comparison in performance returns the stored vector closest to the singing. Fricatives and pitched consonants are also detected, as are duration, amplitude, and 'pitchiness' of each vowel. This, as well as silence between vowels and between the onset of vowels, is all parsed to the graphics engine as performance effort information for further processing.
Visualization of voice
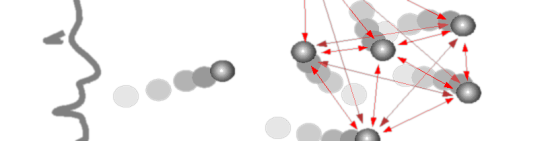
When a sound is recognized, a particle (“phonemon”) is sent into the 3D space with its corresponding attributes:
- its speed is attributed according to the amplitude of the voice,
- its mass is given according to the the duration of the phoneme,
- its life time is given according to the delay after the previous phoneme,
- and its type represents the class in the phoneme recognition.
The louder the voice is, the faster the particles go. The slower the speech is, the longer the transformation will take and the heavier the particles will be. Visually, we chose to represent particles by bright points (contrasting with the dark environment) with different color and size (according to their type and mass respectively).
Then, the “phonemons” start to interact with each other in a spring-mass particle system. Eventually, the particles would converge to a 3D shape representing the pronounced word/sentence. For instance, a word of three phonemes would lead to a triangle, and word of four phonemes to a tetrahedron. The last phase of the transformation consists in the simulation of forces enforcing an organization of “phonemons” in space which corresponds to the original organization of the phonemes in speech. Like this, two different words of the same length becomes two different shapes with the same topology.
It is important to notice that, at the end of the speech-to-3D transformation, phonemes' duration and type have been conserved and integrated in the geometric structure (as mass and distance). To the opposite, voice amplitude have been transformed into dynamic factors (the speed of each particle being transferred to the shape as kinetic energy).
Publications
Herbelin B., Lasserre S. and Ciger J. (2008). Flying Cities: building a 3D world from vocal input. Journal of Digital Creativity, 19(1):62-72. Taylor & Francis Publisher (online access).